


Bay Area Tech Blog #59 - Generative AI
NVIDIA GTCセッション「Generative AIの謎を解き明かす」


はじめに
NVIDIA GTCとはAIとメタバースの開発カンファレンスでオンラインにて開催されています。基調講演によると今年の参加者は25万人だったそうです。カンファレンスは2023年3月23日に終了しましたが、まだ参加を受け付けており4月10日まで録画を日本でも見ることができます。無料の有意義なイベントですのでぜひご覧ください。
本日は、650以上のセッションから良かったものをレポートします。タイトルは「Generative AIの謎を解き明かす」で、スピーカーはNVIDIAの応用ディープラーニング研究担当副社長であるブライアン・カタンザロ氏です。全てを書ききれないため、ハイライトを報告いたします。
GPT言語モデルの歴史
言語モデルの学習方法 Few shotとZero shot
人間による微調整
オムニバースをGenerative AIで作るには
1. GPT言語モデルの歴史
Generative AIは今まさに出てきたように見えますが、15年以上前から盛り上がっている分野です。
GPTの最初のバージョンは2018年にリリースされました。その時点でGPTが成し遂げた事は、単語の品詞を予測するという単純なタスクでも高い精度を出すことができたことでした。しかし、GPTが本当に革新的だったのは、その学習モデル(入力データに対して結果を導き出す仕組み)にあります。通常、単語の品詞を予測するためには、その単語がどの品詞に属するかを示すラベルが付いた例を学習する必要があります。しかし、そのようなラベルつきの例は限られています。そのため、GPTは大量のテキストを教師なし学習することができるように設計されました。
GPTは、膨大なテキストを学習することで、より深い意味を理解し、様々な問題に対処することができるようになりました。
GPT2は2019年に登場し、表現力に優れ、長文でまとまりのあるテキストを生成できるようになりました。一貫した構造を持つテキストを生成するために、文中の遠く離れた単語同士の関係性をモデル化することができるようになりました。
翌年に発表されたGPT3になるとモデルが100倍の大きさになりました。そのおかげで、言語モデルは単に文章を理解するためのツールではなく、問題解決できるツールだと分かり始めました。この後出てきます、Few shotとZero shotの問題解決方法ができるようになりました。
Web GPTはWeb検索のようなツールを使うようになりました。ツールによってモデルがアクセスできる情報の範囲が拡大しました。インストラクターGPTは、人間からのフィードバックを使って人間の価値観や原則により沿うようモデルを調整できることを示しました。
そして、2022年末に発表されたChat GPTは、複数のタスクを同時に処理する能力を拡張しました。これにより、1つのタスクに関する情報を別のタスクに転用することができます。このモデルは、並外れたインタラクティブ性とテキスト生成能力によって、メインストリームに到達しました。進歩は急速で、長い間この分野に取り組まれてきた成果が蓄積されています。
2. 言語モデルの学習方法 Few shotとZero shot
Few shot学習とは、言語モデルがごくわずかな例で学習することができることを指します。例えば、英語の文章に対するスペイン語の翻訳を数例学習させると、言語モデルは次の英語の文章をスペイン語に翻訳することができます。これは、英語とスペイン語が別々の語彙や文法を持つ別々の言語であることを理解しているためです。
Few shot学習の大きな利点は、これらの言語間に直線的な対応関係がないことにあります。言語モデルは与えられたタスクを解決するために、言語、言語の構造、英語とスペイン語の文法や語彙など、自身が知っているすべての情報を利用します。つまり、大量の翻訳された並行テキストが与えられなくても、インターネット上の膨大な量のテキストで訓練された言語モデルが、与えられたタスクを解決することができるということです。
そして、さらに進んだものが、Zero shot学習です。
Zero shot学習とは、モデルに具体的な例を与えずに、新しいタスクを解決する能力を持たせることを指します。例えば、言語モデルに英語からスペイン語への翻訳を依頼する際に、具体的な翻訳例を与えずに英語の文章を書き、「これをスペイン語にしてください」と説明することで、モデルが依頼を理解し、正しい翻訳を出力することができます。
言語モデルは、Zero shot学習によってチェスのような異なる分野でのタスクを遂行することができるようになりました。このようなタスクを遂行するためには、モデルがチェス盤の状態空間の表現を構築できる必要があります。そして、言語モデルは微調整によって、チェスのルールについてのテキストを学習することができます。
言語モデルは、単に表面的な理解だけでなく、データの背後にある意味を深く理解するデータ構造を構築することができます。これにより、あらゆる種類の道具について言語で説明し、モデルが実際にその道具を手に取って使い始めるように訓練することができます。つまり、モデルはツールを使うようにトレーニングされます。
3. 人間による微調整
言語モデルの作成には、事前訓練とフィードバックによる微調整が必要です。事前訓練では、膨大な量のデータを用いてテキストを理解しますが、インターネット上のテキストは問題解決に最適な形式で書かれていません。例えば、ニュース記事には、見出しがあり、本文にはさまざまな事実が書かれていますが、その中に問題文はありません。問題解決能力を向上させるためには、人間のフィードバックが必要なのです。
実際に、GPTではモデルを作成する際に、たくさんの問題文を集め、その問題に対する解決策を、解決策の書き方を知っている専門家に書いてもらいます。そして、言語モデルを微調整して、言語モデルが主に問題解決に使用されることを認識させ、問題を提示して解決策を出力するようにモデルを訓練するのです。
モデルができたらモデルの出力に順位をつけて人間が評価します。最後には、強化学習と呼ばれるものを使って、実際にモデルを自分自身と戦わせます。
人間のフィードバックによる教師ありの微調整や強化学習が重要な役割を果たすことで、モデルがより便利になります。さらに私たちの価値観に沿った出力が生成される様になりより安全なものにもなることも注目すべき点です。
4. オムニバースをGenerative AIで作るには
オムニバース内で人々が相互に影響し合って問題を解決するために、Generative AIを使ったコンテンツが登場します。
画像とテキストを関連付ける「Image embeddings」という技術があります。これは、大量のキャプション付き画像を収集して学習させることで、画像の内容を説明するキャプションを自動生成するものです。
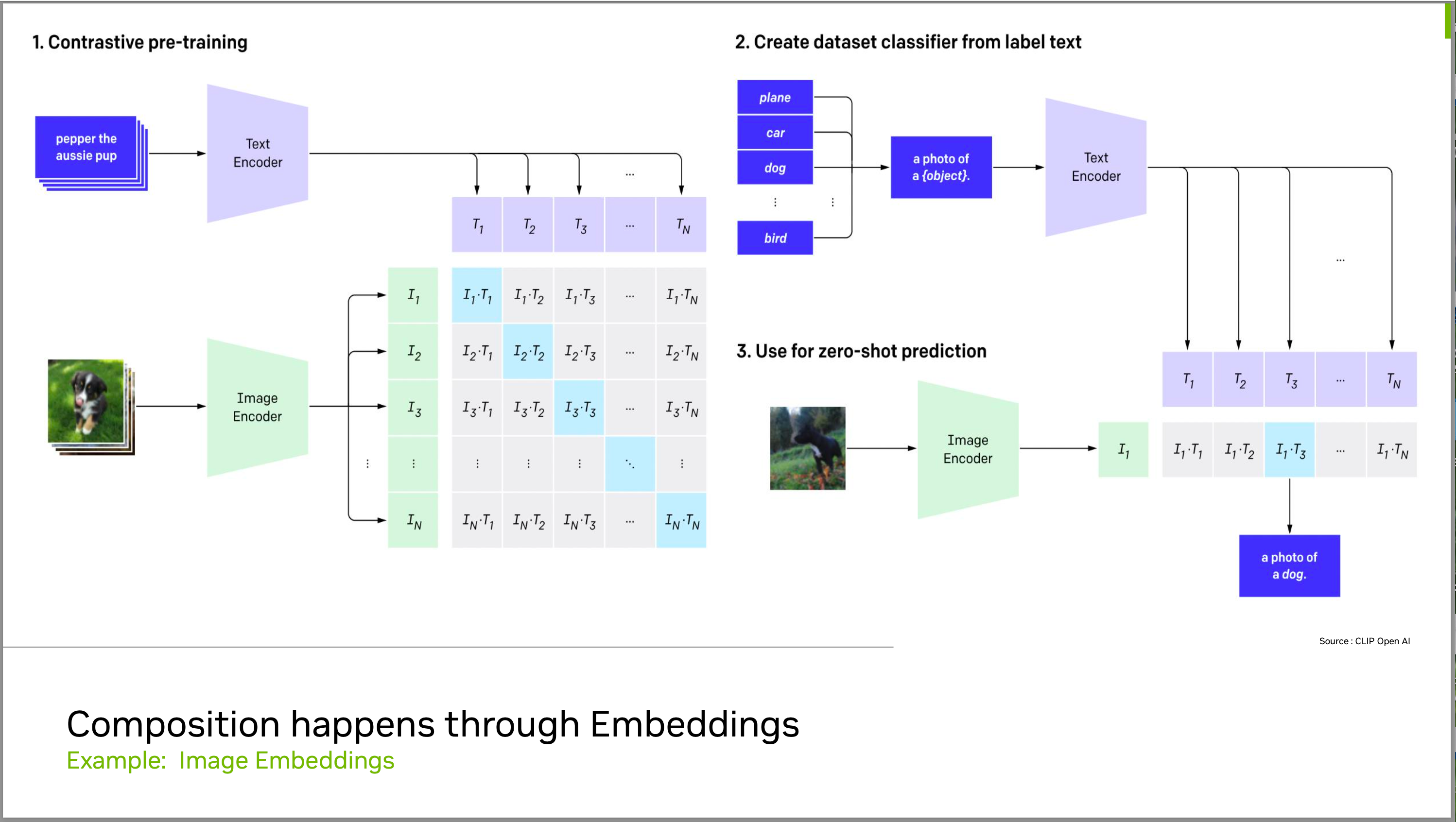
学習過程では、大量の画像とテキストの組み合わせを使って、ニューラルネットワークをトレーニングします。これにより、画像とテキストの関係を理解するための空間が作成されます。この空間は、各画像とテキストの組み合わせに対して、それぞれベクトル(例えば、二次元空間における点を表す場合、その点の位置を x 方向と y 方向の二つの数値で表し、これを並べた二つの数値のペアがベクトル)を生成します。このベクトルをエンベッディングと呼びます。
このエンベッディングを使用することで、テキストを空間に埋め込み、その埋め込みから画像を生成することができます。逆に、画像からエンベッディングを生成し、その空間内でテキストを生成することもできます。このように、エンベッディングを使用することで、画像とテキストの間の関係を理解し、生成することができます。
これは、多くの種類のデータから学習することができます。例えば、Lion Five Bというデータセットには、約60億枚のテキスト付き画像が含まれています。これを使用することで、ニューラルネットワークはより正確なエンベッディングを生成することができます。
NVIDIAは、テキストを基に3Dモデルを生成するMagic 3Dを開発しました。この技術は、従来の画像に限らず、3D空間でも機能することが可能であり、オムニバースのような仮想世界に新たな種類のオブジェクトを作成することができる可能性を秘めています。
おわりに
「すごい」と思っていたテクノロジーが、少し身近になった気がしませんでしたか?NVIDIAでは、AIに関するセルフトレーニングを用意しています。無料のものから数十ドル程度のものまで、気軽に始められるコンテンツがあります。私たちに身近なインフラに関するものも含まれています。
この機会に、一緒にAIの旅に出ましょう!